
Resources
- ORena SAVE FOCUS structured Challenge Design - FRAME Track: LINK
- ORena SAVE FOCUS Submission Template Code: Will be released soon
- ORena SAVE FOCUS Evaluation and Ranking Toolkit: Will be released soon
- ORena SAVE FOCUS first data batch: HeiCo-FOCUS-VQA
- ORena SAVE FOCUS second data batch: LapChole-FOCUS-VQA
All Training Data
The complete ORena SAVE FOCUS training data will consist of two batches. The VQA pairs are generated and quality-controlled by expert annotators.
|
First training data batch 30 colorectal surgery videos |
Second training data batch 170 laparoscopic cholecystectomy videos |
Total training videos 200 videos |
Total VQA pairs 50,000 questions |
The data will be hosted via Hugging Face and can be accessed conveniently through the ORena SAVE FOCUS Python package.
First Training Data Batch
The first training data batch is based on the HeiCo-FOCUS dataset, built on {Hei}delberg {Co}lorectal surgeries. HeiCo-FOCUS contains 30 colorectal surgery videos and 15,000 VQA pairs covering five core capability groups: object recognition and identity matching, temporal grounding, aggregation, event and procedural understanding, and complex reasoning.
For the FRAME Track, the first training data batch contains 6,000 single-image VQA pairs. These questions focus on information that can be inferred from a single laparoscopic image, such as visible foreign object identification, counting, attributes, and spatial localization.
As also can be seen in Figure 1, HeiCo-FOCUS was constructed through a rigorous multi-stage annotation pipeline involving large-scale annotation and 39 domain experts to ensure high quality and clinical relevance. To systematically probe model behavior, the benchmark uses a multi-track evaluation framework that progressively increases temporal and contextual demands from single frames to full procedures.
Extensive experiments demonstrate that HeiCo-FOCUS pushes current VLMs to their limits: although leading models substantially outperform blind baselines, top overall Accuracy remains below 60% across all context lengths and drops to 37% on long-horizon PROCEDURE tasks. We therefore expect HeiCo-FOCUS to serve as a catalyst for the development of models capable of reliable, temporally consistent reasoning over hours-long videos.
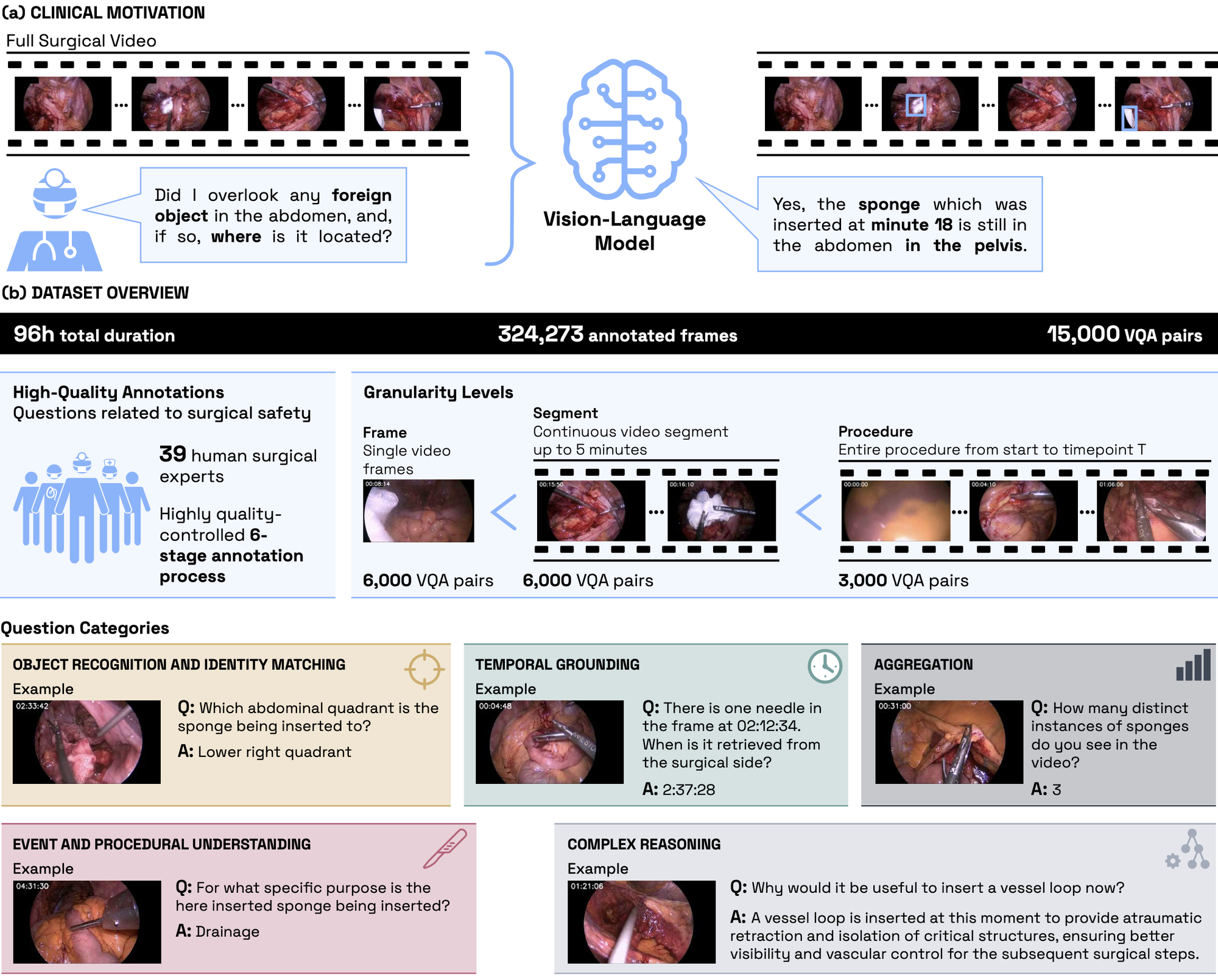
Figure 1:
Overview of the HeiCo-FOCUS benchmark. a) Clinical motivation. Ensuring the retrieval of
foreign objects at the end of a surgery is critical, as retained objects can lead to severe
complications. b) Dataset overview. The dataset comprises 96 hours of surgical video annotated
with 15,000 visual question answering (VQA) pairs spanning five core capabilities.
Our taxonomy for surgical VQA is depicted in Figure 2. For question categorization, each question is assigned to one primary capability category and may optionally be tagged with additional secondary sub-categories to reflect its multi-faceted nature. The primary category is determined by the dominant reasoning requirement of the question. For example, “Where” questions are assigned to object recognition and identity matching ➡ spatial localization, “How many” questions to aggregation, and “When” questions to temporal grounding ➡ temporal localization. This primary assignment enables the balancing of VQA pairs across capabilities while secondary labels allow fine-grained stratified evaluation. The complete taxonomy is provided further below.

Figure 2:
HeiCo-FOCUS taxonomy with sample questions.
Second Data Batch
The second data release introduces the LapChole-FOCUS dataset — 170 laparoscopic cholecystectomy videos that have not been made public before — and additionally extends HeiCo-FOCUS with a further 15,000 questions following the same track distribution as the first release. Together, this release adds 35,000 VQA pairs, bringing the total to 50,000.
The second data batch will contain:
HeiCo-FOCUS Extension
An additional 15,000 VQA pairs on the 30 HeiCo colorectal surgery videos, following the same capability taxonomy as the first release.
|
FRAME 6,000 VQA pairs |
SEGMENT 6,000 VQA pairs |
PROCEDURE 3,000 VQA pairs |
LapChole-FOCUS
20,000 VQA pairs on 170 laparoscopic cholecystectomy videos. Of these, 100 videos are fully annotated; the remaining 70 are unlabeled and provided as additional training material.
|
FRAME 6,000 VQA pairs |
SEGMENT 6,000 VQA pairs |
PROCEDURE 3,000 VQA pairs |
Together with the first training data batch, this results in 50,000 training VQA pairs.
Validation and Test Data
Test data will include 200 videos from a broad range of procedures, including cholecystectomies and additional procedure types. These test videos will not be conveyed to participants. Leaderboard validation data will include 20 additional videos representative of the test data.
Validation Set
|
FRAME 2,000 VQA pairs |
SEGMENT 2,000 VQA pairs |
PROCEDURE 1,000 VQA pairs |
Test Set
|
FRAME 20,000 VQA pairs |
SEGMENT 20,000 VQA pairs |
PROCEDURE 10,000 VQA pairs |
Taxonomy
The following taxonomy defines the capability groups and sub-capabilities used to categorize VQA pairs across the ORena SAVE FOCUS Challenge. Not all sub-capabilities are used in every track: the FRAME Track focuses on sub-capabilities that can be evaluated from a single image, while the SEGMENT and PROCEDURE tracks additionally cover temporal and long-context reasoning.
1. Object recognition and identity matching: Recognition of object instances, their semantic type, attributes, spatial context, and identity consistency across time. Subcategories:
- 1a. Object identification: semantic classification of visible object instances
- 1b. Object instance identity matching: correspondence of object instances across time
- 1c. Object attributes and state: recognition of observable object properties or handling states
- 1d. Object spatial localization (camera): object localization relative to the image plane
- 1e. Object spatial localization (situs): object localization relative to anatomical structures
2. Temporal grounding: Localization of events or object occurrences within the video timeline, including their temporal position and duration. Subcategories:
- 2a. Temporal localization: identification of the time point or interval at which an event or object occurrence takes place
- 2b. Duration estimation: estimation of the temporal extent for which an event or object occurrence persists
3. Aggregation: Combination of information on foreign objects and events across multiple objects, instances, and/or time points. Subcategories:
- 3a. Object aggregation: aggregation of information across multiple foreign object instances and/or categories
- 3b. Event aggregation: aggregation of events that involve foreign objects across time
4. Event and procedural understanding: Recognition and interpretation of actions, events, and their procedural structure over time. Subcategories:
- 4a. Foreign object interaction recognition: identification of actions or manipulations involving a foreign object
- 4b. Foreign object usage purpose: identification of the general procedural role of a foreign object at a given time. Answers are grounded in what is visually demonstrated; no inference about hypothetical outcomes or hidden intent
- 4c. Temporal ordering: determination of the relative order of events or procedural steps, including the identification of the n-th event in a series of events
5. Complex reasoning: Inference of functional, causal, relational, or outcome-related information beyond direct observation, and reasoning over interactions, dependencies, comparative patterns, and temporally extended evidence across objects and events. Subcategories:
- 5a. Functional reasoning: inference of the intended function or role of an object or action beyond what is directly shown
- 5b. Causal and consequence reasoning: inference of cause–effect relationships between actions, events, or object states and inference of potential or actual outcomes resulting from actions or events
- 5c. Multi-step compositional reasoning: inference that requires the execution of a sequence of interdependent reasoning steps across objects, space, and time, involving the decomposition of a query into multiple sub-tasks to derive an answer that cannot be attributed to a single dominant capability