
ORena SAVE FOCUS Challenge — FRAME Track
Foreign Object Contextual Understanding in Surgery
Highlighted announcementsThe second data batch (LapChole-FOCUS VQA) has now been released. It contains 170 laparoscopic cholecystectomy videos and is available on Hugging Face! 👉 Hugging Face |
Single-image surgical VQA for foreign object understandingThis is the FRAME Track of the ORena SAVE FOCUS Challenge. The track evaluates whether vision-language models can answer clinically relevant questions from a single laparoscopic image, focusing on foreign object identification, counting, attribute recognition, and spatial localization. The broader ORena SAVE FOCUS Challenge benchmarks vision-language models on clinically grounded visual question answering for foreign object understanding in minimally invasive surgery. The goal is to advance AI methods that can support intraoperative quality assurance and patient safety. The FRAME Track is the most accessible entry point into the challenge. It tests core surgical scene understanding before participants move to the temporally more demanding SEGMENT and PROCEDURE tracks. |
Start here |
Why this challenge matters
Clinical relevanceIn minimally invasive surgery, foreign objects such as sponges, needles, clips, drains, specimen bags, and similar objects may be introduced into the abdominal cavity during a procedure. Retained foreign objects after major operations are rare but clinically relevant adverse events associated with patient harm [Badiee et al., 2025]. |
Technical challengeForeign object understanding requires robust visual recognition, spatial reasoning, and, in the video-based tracks, temporal consistency over long time horizons. Long-horizon tracking is especially challenging because models must maintain object identity through insertion, manipulation, occlusion, disappearance, and retrieval events [Weprin et al., 2021]. |
Benchmark at a glance
|
Task type Surgical visual question answering |
Input surgical RGB image, meta data (type of procedure, timestamp) + question |
Output short text answer |
Focus Foreign object understanding |
|
FRAME time budget 5 seconds per question |
FRAME hardware 48GB VRAM GPU |
Prize pool $60k+ across tracks |
Submission Docker container |
The three ORena SAVE FOCUS tracks
FRAME
|
SEGMENT
|
PROCEDURE
|
FRAME Track
The FRAME Track evaluates a model’s ability to answer clinically relevant questions from a single image. The task targets core surgical scene understanding skills such as:
- foreign object identification
- foreign object counting
- attribute and state recognition
- spatial localization in the image or surgical scene
- basic safety-relevant interpretation of laparoscopic images
The input consists of a single image and a question. The submitted algorithm must return a text answer. All methods must be fully automated.
Algorithm inputSurgical RGB image, meta data (type of procedure, timestamp), question Exact input format will follow the official submission template repository. |
Algorithm outputShort text answer Exact answer formatting and validation details will follow the official submission template repository. |
Data and scientific background
The first released data batch, HeiCo-FOCUS, is based on Heidelberg colorectal surgery videos and provides clinically grounded VQA pairs for foreign object understanding. The dataset covers five capability categories: object recognition and identity matching, temporal grounding, aggregation, event and procedural understanding, and complex reasoning.
The FRAME Track builds on prior work in surgical visual question answering, where models answer clinically relevant questions from surgical scenes [Seenivasan et al., 2022].
For the FRAME Track, the focus is on the single-image part of this benchmark. This provides a controlled setting for evaluating whether models can recognize and localize safety-relevant foreign objects before moving to temporally extended reasoning in the SEGMENT and PROCEDURE tracks.
|
First data batch HeiCo-FOCUS VQA |
Number of videos 30 |
Expert involvement Clinical and technical experts |
Motivation Foreign object safety |
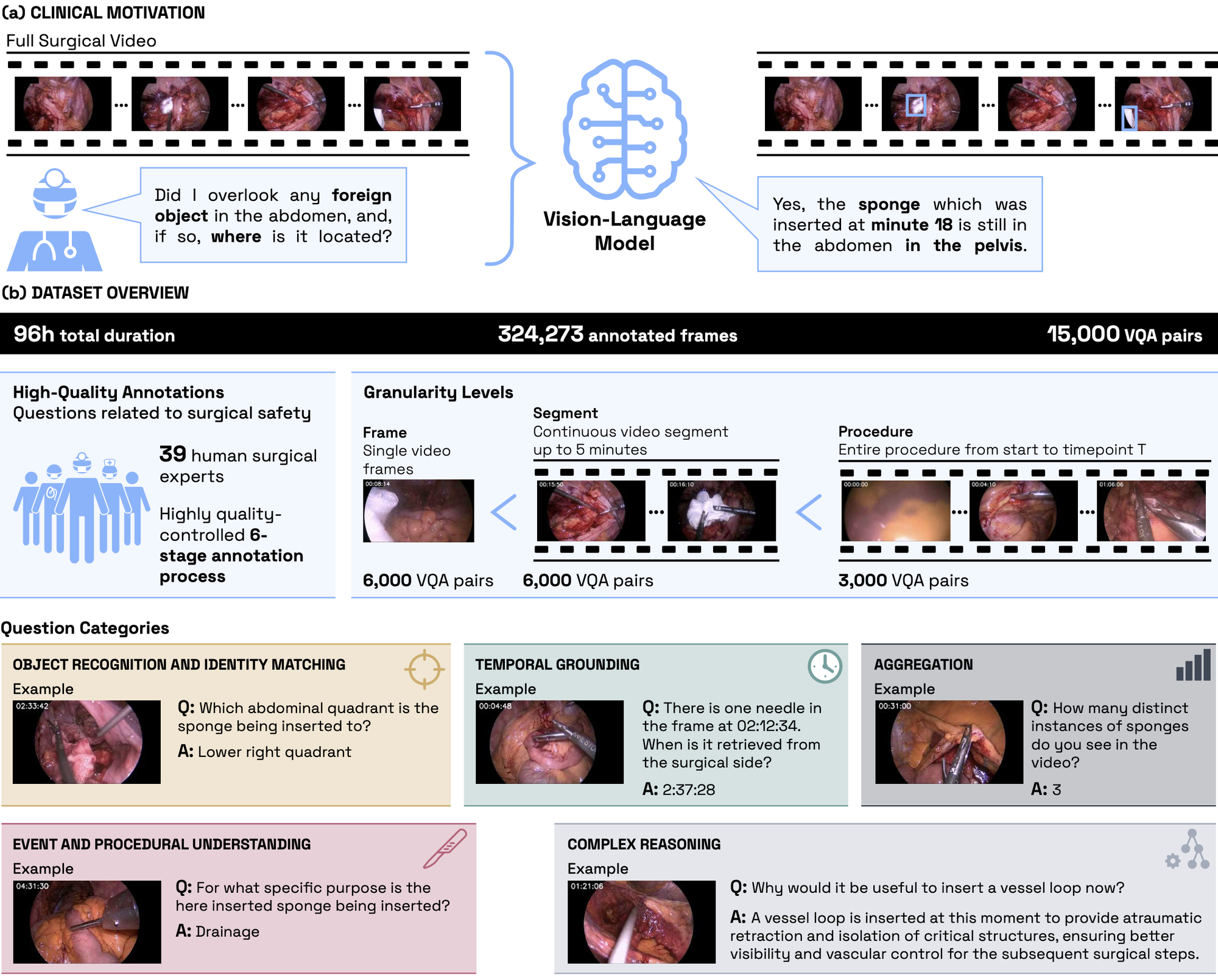
Figure 1: Overview of the HeiCo-FOCUS benchmark, showing a) the clinical motivation and b) providing an overview of the first batch dataset.
|
Second data batch LapChole-FOCUS VQA |
Number of videos 170 |
Expert involvement Clinical and technical experts |
Motivation Foreign object safety |
Submission and evaluation
- Submissions must be made through the challenge website.
- Algorithms are submitted as Docker containers.
- Containers must run without internet access.
- Inference is limited to a single GPU.
- The FRAME Track time budget is 5 seconds per question on a 48GB VRAM GPU.
- During pre-evaluation, each team may submit up to 10 times, subject to possible adjustment depending on compute constraints.
- Only teams that beat the baselines on the leaderboard proceed to the final test stage.
- Teams must submit a method description with sufficient technical detail for interpretation of the results.
Prizes and recognition
$60k+ prize poolA prize pool of at least $60k has been secured across the ORena SAVE FOCUS Challenge tracks. The FRAME Track is planned to receive approximately 20% of the total prize money. |
Publication opportunityTeams that beat the baselines may be invited as co-authors on the planned challenge publication, subject to the official rules and submission requirements. |
Resources
| Registration | Register for the ORena SAVE FOCUS Challenge |
| Central forum | ORena SAVE FOCUS Forum |
| First data batch | HeiCo-FOCUS VQA on Hugging Face |
| Second data batch | LapChole-FOCUS VQA on Hugging Face |
| Python package | orena-focus GitHub repository |
| Submission template | Will be released soon. |
Webinar recording
The ORena SAVE FOCUS webinar recording is available here after May 28th: